Auch wenn die Benutzeroberfläche grundsätzlich anstrebt selbsterklärend zu sein, erfordern einige Funktionalitäten ein gewisses Maß an Hintergrundwissen, um verstehen zu können, was im Detail passiert und welche Möglichkeiten sich einem bei der Arbeit bieten. Dieses Kapitel beschreibt die Benutzeroberfläche mit ihren wesentlichen funktionellen Möglichkeiten und Hintergrundprozessen.
Der Einfachheit halber folgt das Kapitel dem Aufbau der Benutzeroberfläche mit seinem in Abschnitte gegliederten Menü. Bei den Abschnitten links am Bildschirmrand handelt es sich um »Surveys« und »Main«. »Reporting« bleibt außen vor, weil der Abschnitt nur erscheint, wenn für eine Studie im Bereich »Surveys« unter dem Menü-Punkt [Reporting Setup] das Reporting eingerichtet wurde. Alles Wesentliche zum Thema Reporting findet sich daher im „Reporting setup“, wenn es um die Konfiguration des Reportings geht.
Die Einträge unter »Surveys« beziehen sich ausschließlich auf die im Ausklappmenü gewählte Studie. Das setzt natürlich voraus, das bereits ein Fragebogen angelegt ist. Sollte das nicht der Fall sein, erklärt „Survey Manager - Anlegen neuer Studien“ wie eine neue Studie angelegt werden kann. Außerdem muss der angemeldete Nutzer Zugriffsrechte auf eine Studie haben, sonst erscheint der Abschnitt »Surveys« nicht. Menü-Punkte unter »Main« beziehen sich dagegen auf die Funktionalität des Systems insgesamt als Server und Verwaltungsoberfläche.
Interviews beginnen im Normalfall, wenn die Befragten die ihnen mitgeteilte URL ansteuern (reine Online-Befragung) oder das Tablet mit dem laufenden Fragebogen übergeben bekommen. Für andere Szenarien hält die Web-Oberfläche von Q. im Bereich »Surveys« mit dem Punkt [Start] eine weitere Möglichkeit bereit. Da die Menü-Punkte im Bereich »Surveys« nur auf die im Ausklappmenü gewählte Studie beziehen, sollte sicher gestellt sein, dass hier die richtige ausgewählt ist.
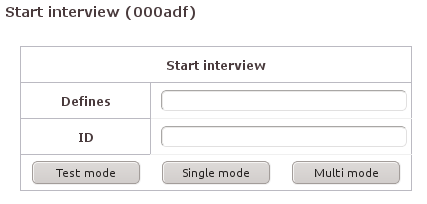
Die Maske kann für den Test beim Entwickeln des Fragebogens mit dem Klick auf [Testmode] das Interview im Test-Modus starten. Für den Start des Interviews im Single-Mode (jeder Befragte meldet sich mit einer individuellen ID an) oder Multi-Mode (mehrere Befragte verwenden eine gemeinsame ID) muss die ID im entsprechenden Feld mitgegeben werden. Genaueres zu IDs folgt in „ID settings“.
Zu Testzwecken kann hier beim Start des Interviews noch eine »Define-Anweisung« übergeben werden, wie sie in „ Define “ erläutert sind.
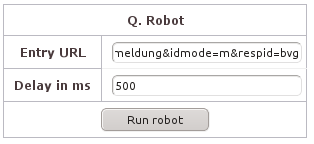
Das Startmenü bietet neben den regulären
Möglichkeiten, ein Interview zu starten (test-,
single-, multimode) auch die Option, einen Robot
durch das Interview zu schicken. Dazu setzt der
Server den dort installierten Browser Firefox ein,
um ihn ohne sichtbare Rückmeldung von jedem Screen
einen Screenshot machen zu lassen. Die Maske
verlangt die Vorgabe einer URL, ab der der Robot
einsetzen soll. Die Angabe eines Zeitraums zwischen
den Aufnahmen ist optional. Mit den Skriptparametern
ignoreFilter,
ignoreAssert und
ignoreNoMissing (s. „Skriptparameter“) lässt sich vom Skript
aus beeinflussen, wie der Robot sich durch das
Skript bewegt. Nach dem Durchgang bietet der Browser
an, ein Zip-Archiv herunter zu laden, das die
Screenshots als PNG-Dateien enthält.
Gedacht ist die Möglichkeit, den Roboter einzusetzen, zu Dokumentationszwecken um den vollständigen Fragebogen auszudrucken (dann sollten alle drei Skriptparameter mit »yes« eingeschaltet werden). Das sollte vor dem Start einer Studie geschehen, weil das Programm mit jedem Lauf ein eigenes Interview erzeugt. Außerdem kann der Robot verwendet werden, um ein konkretes Interview auszudrucken oder am Bildschirm nachzuvollziehen, wie es unter dem Menüpunkt [Data / Export] und dort unter [Native Data] möglich ist.
Man kann den Befragten auf diese Weise auch
ermöglichen, den von ihnen ausgefüllten Fragebogen
herunter zu laden. Die interne Variable
_encryptedcaseid erlaubt es, die
URL zu veröffentlichen, weil die Fallnummer nur
verschlüsselt erscheint und so keine Rückschlüsse
auf andere gültige URLs zulässt.
group grp_finished;
labels=
1 "Vielen Dank für Ihre Teilnahme. Ihren Fragebogen finden sie hier: http://server.de/SurveyServlet?action=printcase&survey=test&lfd=@insert(_encryptedcaseid)" (_finished eq 1)
2 "Vielen Dank für Ihr Interesse. Leider passen Sie nicht zu unserer Zielgruppe." (_finished eq 2)
3 "Vielen Dank für Ihr Interesse. Leider haben bereits ausreichend Personen mit Ihrem Profil an dieser Befragung teilgenommen." (_finished eq 3)
;
Der Link funktioniert auch ohne Anmeldung am Server und die Studie muss dazu nicht aktiv sein.
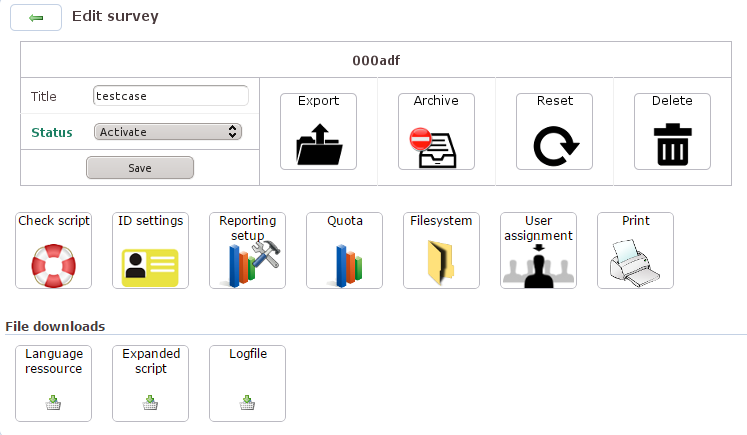
Unter dem Stichwort [Configure] hält die Web-Oberfläche eine ganze Reihe von Möglichkeiten bereit, an den Stellschrauben der Studie zu drehen. (Bitte sicherstellen, dass im Ausklappmenü die richtige Studie ausgewählt ist.)
Zur Verfügung stehen nur aktive Studien. Studien,
die über den [Survey Manager] der Web-Oberfläche
angelegt wurden, sind automatisch aktiv, weil die
Datei active.cfg beim Erstellen
des Gerüsts für die Studie in das
Fragebogenverzeichnis kopiert wurde. Die Datei dient
Q. als Schalter: ist sie vorhanden, gilt die Studie
als aktiv, ist sie nicht vorhanden, ist der
Fragebogen nicht aktiv. Der Mechanismus erweist sich
insbesondere dann als nützlich, wenn etwa die
vorgegebene Zahl an Interviews erreicht ist und die
Studie deaktiviert werden kann. Nachzügler sehen
dann automatisch eine Nachricht, dass die Studie
bereits geschlossen wurde (s. auch Konfigurationsdateien im Fragebogenverzeichnis).
Bei einem Klick auf Export wird die vollständige
Studie (Fragebogen- und Medienverzeichnis) in einer
Q.-Projektdatei archiviert und zum Download
angeboten. Die Datei trägt zwar die Endung
.qp, aber es handelt sich um
ein Zip-Archiv.
Wenn in der Konfigurationsdatei qonline.cfg (s.
„Konfigurationsdatei qonline.cfg“) der Parameter
archivePath gesetzt ist (z.B. auf
archive, dient das Verzeichnis
archive in der Wurzel der
Q.-Installation als Archiv. Wenn der Parameter nicht
gesetzt ist, erscheint das Icon für [Archive] mit
einem »Einfahrt verboten«-Schild und bleibt ohne
Funktion.
Bei aktivierter Archiv-Funktion fasst Q. den
Studien- und den Medienordner in einem Archiv
zusammen, komprimiert die Datei und legt sie unter
dem Namen der Studie mit der Endung
.qp im Archiv-Verzeichnis ab.
Vorsicht: Zugleich mit dem
Verschieben ins Archiv löscht Q. die entsprechenden
Verzeichnisse der Studie im surveys- und im
media-Ordner.
Der Knopf [Reset] bereinigt das Studienverzeichnis
und setzt die Studie auf den Ausgangspunkt zurück.
D.h. Protokoll-Dateien werden entfernt, ID-Listen
und Quoten zurückgesetzt, auch laufende Interviews
werden gelöscht. In der Regel dürfte sich die
Funktion als praktisch erweisen, wenn es darum geht,
Testdaten zu beseitigen und die Studie für die
eigentliche Befragung frei zu schalten. Wenn
backupPath in qonline.cfg
definiert ist (s. „Konfigurationsdatei qonline.cfg“.), legt Q. beim Reset eine Sicherungskopie im dort
festgelegten Verzeichnis ab.
Im Lauf auch des Testbetriebs legt Q. Verwaltungsdaten im Fragebogenverzeichnis an. Dazu gehören die Dateien
respo.lst, in der Q. Buch führt über die IDs, mit denen sich Teilnehmer anmelden. (Die Datei kann auch vorgegeben werden s. „ID settings“.)surveylog.lst, in der Q. Protokoll führt über die einzelnen Interviews mit Start- und Endzeiten und der letzten beantworteten Frage.In
lfdcount.lstzählt Q. die laufende Nummer der Interviews hoch. Datei und Nummer bleiben auch bei einem Reset erhalten.Wenn unbekannte IDs erlaubt sind, vermerkt Q. die verwendeten IDs auch in
id_unknown.lst.
Löscht die Studie (Fragebogen- und Medienverzeichnis), wenn die dazu erneut abgefragten Anmeldedaten korrekt eingegeben wurden.
Beim Skripten von Fragebögen gibt es verschiedene Möglichkeiten, sich bei der Fehlersuche zu behelfen. Neben der Ausgabe von Variablen in speziellen, zusätzlich eingefügten Debug-Fragen, leistet vor allem der Skriptcheck Hilfestellung. Q. prüft das Skript auf syntaktische Korrektheit und gibt entsprechende Fehlermeldungen aus bzw. warnt vor möglichen Fehlerquellen. Dazu gehören z.B. (sich überschreibende) Mehrfachzuweisungen von initActionBlock, resumeActionBlock, startActionBlock, etc. oder im Skript definierte Fragen, die gar nicht oder mehrfach im Befragungsablauf enthalten sind. Außerdem informiert der Skriptcheck über die Gesamtzahl der Screens und hilft damit beim Abgleich des Fortschrittsbalkens.
Änderungen am Skript können parallel vorgenommen und das Skript dann über den Knopf »erneut laden« wieder überprüft werden.
Fehler weist das Programm oben in der Seite im Bereich der Zusammenfassung als Link in dunkelrot aus. Der Link verweist auf die Fundstelle im darunter folgenden vollständigen Bericht. Eine konkrete Zeilenzahl zur Fundstelle des Fehlers kann Q. nicht liefern, denn bevor Q. das Skript abarbeitet, wird es aus den Einzelteilen, aus denen es bestehen kann, zusammengesetzt. Von daher muss man sich an dieser Stelle mit der ungefähren Fundstelle der Fehlerquelle, etwa den Hinweisen auf die Frage davor und danach, begnügen.
Warnungen gibt das Programm in chartreuse (einer Art
hellgrün) aus. Dabei kann es sich um Hinweise auf
Bezeichnungen handeln, die in der Blacklist
auftauchen oder um Fragen, die zwar geskriptet sind,
aber in keinem Block berücksichtigt werden. Das
Programm warnt auch bei bestimmten Bedingungen, etwa
Filter, die einen Array allgemein ansprechen und
nicht einen konkreten Wert des Arrays. Ein Skript,
das Warnungen verursacht, ist lauffähig. Allerdings
kann es, gerade bei lax formulierten Filtern,
Missverständnisse beinhalten, die zu Fehlern in der
Befragung führen. Von daher ist eine seegrün
unterlegte Bestätigung: Script check finished
successfully! durchaus wünschenswert.
Über [ID settings] können die Bedingungen für die zu verwendenden IDs festgelegt werden.
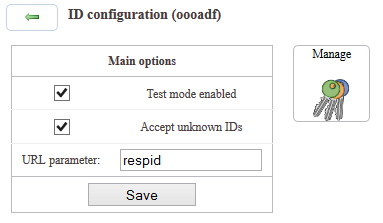
Der Haken bei »Test mode enabled« legt fest, dass eine Studie auch im Testmodus aufgerufen werden kann. Der Haken bei »Accept unknown IDs« ermöglicht die Teilnahme, ohne dass die Befragten sich mit einer hinterlegten ID ausweisen müssen.
Der »URL Parameter« legt fest, mit welchem Variablennamen Teilnehmer-IDs
in der URL bezeichnet werden (Voreinstellung: respid).
Bei der Anbindung von Panels spielt das häufig eine Rolle,
weil die Panels hier unterschiedliche Vorstellungen haben.
Auch wenn der Parameter an dieser Stelle frei definierbar ist,
wird innerhalb des Q. Skripts immer mit _respid auf die ID zugegriffen.
Über den Menüpunkt »Manage« können die einzelnen IDs eingesehen und weitere Aktionen vorgenommen werden.
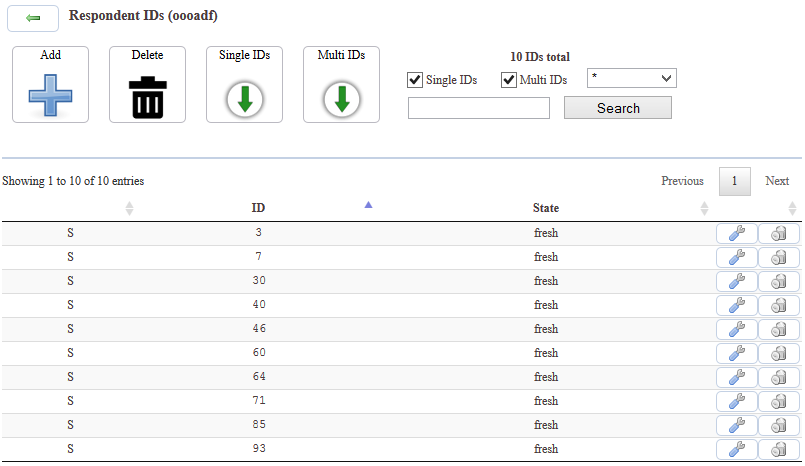
Automatisch werden bis zu 10.000 IDs aufgelistet, außerdem kann gezielt nach IDs gesucht und die Ansicht mit Ein- bzw. Ausblenden der Häkchen auf Single IDs und Multi IDs sowie nach ihrem Status (»fresh« steht für noch nicht und »active« für gerade verwendete IDs, »cancelled« für abgebrochene und »finished« für beendete Interviews) gefiltert werden.
Die einzelnen IDs können in der Bildschirmansicht bzgl. ihres Status geändert oder gelöscht werden. Dies kann beispielsweise nötig werden, wenn IDs zu Testzwecken verwendet und ein ‚Reset‘ der Studie vergessen wurde – dann kann über diese Funktion auch nach Feldstart auf den Status der einzelnen IDs zugegriffen und auf »fresh« gesetzt werden. Auch Probleme mit ‚defekten‘ Links (beispielsweise falls Serverprobleme o.Ä. zu inkonsistenten ID Stati geführt haben) können so behoben werden.
Unter dem Menüpunkt »Add« können neue IDs per Zufallsprinzip generiert werden: Neben der gewünschten Anzahl muss für numerische IDs eine Spannweite definiert werden. Hierbei ist auf einen ausreichend großen Wertebereich im Verhältnis zur gewünschten ID-Anzahl zu achten, da die Software nach 100 zufällig generierten Duplikat-IDs den Vorgang beendet. Alphanumerische IDs werden nach Eingabe der gewünschten Anzahl automatisch 32-stellig aus Groß-, Kleinbuchstaben und Ziffern zwischen 0 und 9 erstellt. Außerdem können schon vorhandene ID-Listen hineinkopiert werden, Duplikate zu bereits bestehenden IDs werden erkannt und ausgelassen.
Mit »Delete« können vorhandene ID-Informationen (Single IDs, Multi IDs oder alle) passwortgeschützt und vollständig gelöscht werden. Dieser Vorgang (und generell alle Einstellungen in diesem Menü) berührt nur die ID-Informationen – Datensätze werden nicht verändert oder gelöscht!
Mit Klick auf die beiden Buttons »Single IDs« und »Multi IDs« werden die aktuellen ID-Informationen zum Download angeboten.
Zu den unterschiedlichen Befragungsmodi (Test, Single, Multi), der Struktur der Einladungslinks und Panelanbindung, siehe auch „Befragungsmodi“.
Welche Aspekte einer laufenden Umfrage im Reporting auftauchen sollen, ist konfigurierbar:
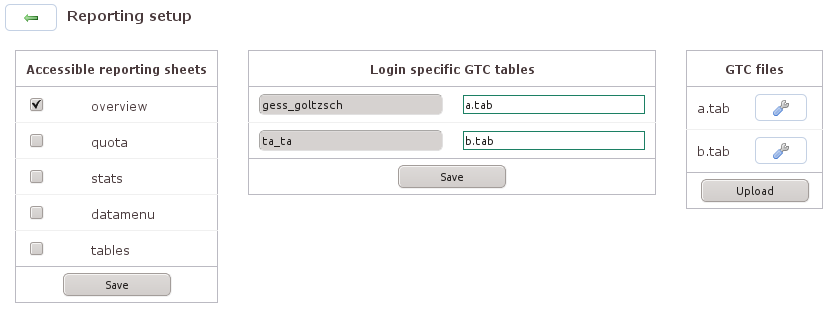
overview
informiert über eine simple Verlaufsgrafik über laufende, beendete und abgebrochene Interviews.
quota
schaltet das Quotenmanagement frei, so dass bei einer laufenden Studie Quotenziele herauf- oder herabgesetzt werden können.
stats
zeigt über den Menüpunkt [Statistics] grundlegende statistische Informationen zur Umfrage: Kontakte insgesamt, Abbrüche, Erfolgreiche, wo abgebrochen, wo beendet usw. Die Informationen illustriert Q. mittels Tortengrafiken.
datamenu
ist noch ohne Funktion.
tables
zeigt die Tabellen, die GESStabs automatisch aus dem aktuellen Datenbestand produziert unter dem Menü-Punkt [GESStabs tables]. GESStabs muss dafür installiert sein.
Änderungen, die über die Web-Oberfläche vorgenommen
werden, wirken sich in der Datei
summary.cfg im
Fragebogenverzeichnis aus, welche die fünf Variablen
(overview, quota, stats, datamenu, tables)
versammelt. Den Variablen wird jeweils
yes oder
no als Wert übergeben.
Wie die GESStabs Tabellen aussehen sollen, lässt
sich über Anweisungsdateien bestimmen
(*.tab-Dateien). Die Dateien
können über den Upload-Mechanismus "GTC files" auf
den Server kopiert werden. Das Verzeichnis
gtc muss im
Fragebogen-Verzeichnis vorhanden sein. Auf diese
Weise können unterschiedlichen Nutzerkonten jeweils
eigene Tabellen zugeordnet werden (»Login specific
GTC tables«).
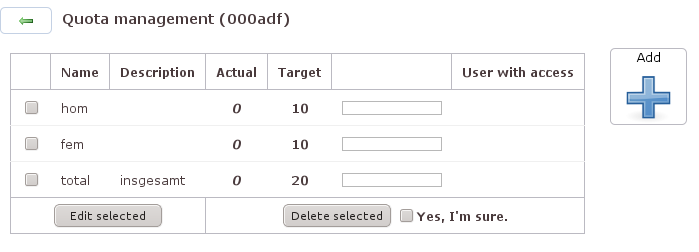
Zum Quoten-Management auf der Administrationsebene
gehören neben dem Editieren selbst auch das
Hinzufügen und Löschen von Quotenvariablen. Die
Variablen und Quotenstände müssen trotzdem innerhalb
des Skripts deklariert und errechnet werden,
Änderungen schlagen sich in der Datei
quotavars.lst nieder.
Unter dem Punkt Filesystem gibt Q. Auskunft über die
Dateien und ihre Codierung im Verzeichnis
text. Früher, langjährige
Nutzer werden sich erinnern, bildete das
Nebeneinander von ASCII, DOS-Codepages und
ISO-Kodierungen öfter ein Problem. Für Q. stellen
unterschiedliche Kodierungen kein Problem dar, sie
werden automatisch erkannt. Die Ausgabe von Q.
erfolgt allerdings immer in UTF-8. Aus diesem Grund
muss im Kopf des HTML-Templates zwingend die Zeile
<meta name="Content-Type" content="text/html; charset=utf-8"/>
erscheinen. Nur so ist gewährleistet, dass die Ausgabe im Browser mit unterschiedlichen Sprachen von Englisch bis Chinesisch kein Problem hat. Außerdem exportiert Q. auch die OPN-Dateien in UTF-8-Kodierung.
Alle Dateien der Liste bietet Q. zum Download an (zweite Spalte), .q-Dateien bietet die Oberfläche über den Schraubenschlüssel auch zum Editieren an, d.h. die Dateien werden direkt in dem Editor geöffnet, der als Standard für .q-Dateien festgelegt ist.
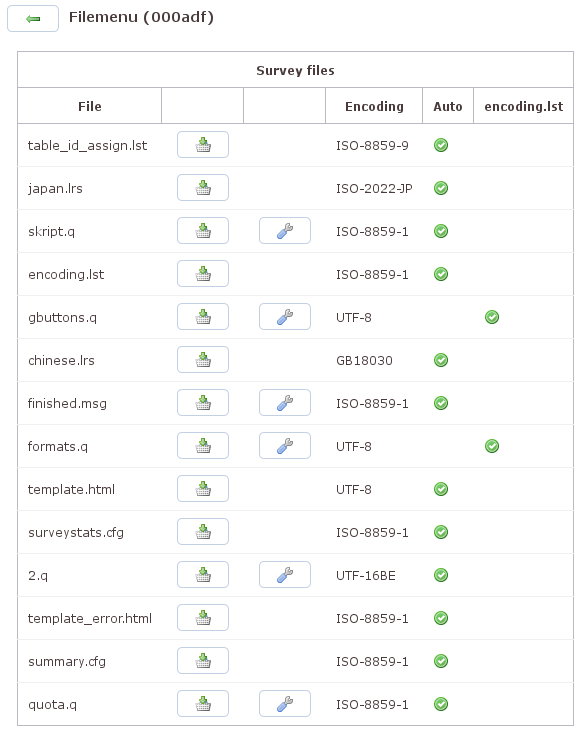
Falls es wider Erwarten doch ein Problem mit den
Kodierungen geben sollte, kann die automatische
Erkennung von Q. mit dem Anlegen der Datei
encoding.lst übergangen
werden. Die Datei ordnet zeilenweise einer Datei
eine Codierung zu in der Form
Dateiname Zeichensatz
Nun gibt es zwar nicht so viele Zeichensätze wie Sand am Meer, aber die Tendenz geht dahin und nicht alle Zeichensätze werden zwangsläufig richtig behandelt. Die kurze Lösung wäre in dem Fall, generell auf UTF-8 auszuweichen.
Unter [User assignment] erscheint eine Liste aller dem System bekannten Nutzer. Die bereits mit einem Haken versehenen Konten haben schon Zugriff auf die aktuelle Studie. Weitere Nutzer können der Studie zugeordnet werden, indem die Checkbox am Anfang der Zeile mit einem Haken versehen und die Liste über den Knopf [Save] gespeichert wird.
Auf diese Weise lassen sich die Einträge in der
Datei access.lst verwalten.
Die Zugriffsrechte der Nutzer auf die Studie werden duch die in der Nutzerverwaltung (unter »Main«, Menü-Punkt [Users]) dem Konto zugeordneten Rechte bestimmt (zum Thema Zugriffsrechte s. „Nutzerkonten und Zugriffsrechte: users.lst“).
Mit [Print] kann nun eine HTML Ausgabe für den geskripteten Fragebogen
als PDF gespeichert oder gedruckt werden. Hier werden alle
Asserts, Filter, Labelattribute dargestellt.
[Print] ist ideal zum Überprüfen von z.B. Filterdefinitionen.
Eine Frage lässt sich als Datensatz verstehen, der verschiedene Felder beinhaltet: Text, Titel, Labels usw. Jedes dieser Felder hat einen eigenen Namen bestehend aus Fragename (z.B. f1) und Feldname (z.B, qqtext), so dass der Fragetext über das entsprechende Feld (f1_qqtext) erreichbar ist. Übersetzungen arbeiten tabellenbasiert: Dem Feldnamen in der ersten Spalte ist der Text in der zweiten Spalte zugeordnet. In welcher Sprache und mit welchem Alphabet der Text verfasst ist, ist dabei unerheblich und so kann für jedes Interview die gewünschte Sprache festgelegt werden, indem den Feldnamen die entsprechende Übersetzung zugeordnet wird.
Die Übersetzungstabelle mit einer Tabellenkalkulation zu erstellen, hat sich in der Vergangenheit zwar als machbar erwiesen, stellte aber auch eine Fehlerquelle dar: HTML-Formatierungen in den Texten gingen verloren, nicht alle Felder wurden übersetzt, weil viele mehrfach erscheinen usw. Daher bietet Q. einen eigenen Ansatz, Übersetzungen zu erstellen und zu verwalten. Das Grundprinzip bleibt dabei erhalten: Den Feldnamen wird in einer Tabelle eine Übersetzung zugeordnet. Aber Q. bringt darüber hinaus einige Besonderheiten mit, die das Übersetzen erleichtern.
Voraussetzung für das Sprachmanagement ist eine
PostgreSQL-Datenbank. Auf welche Datenbank Q. wie
zugreifen soll, legen Parameter in der Datei
qonline.cfg fest (zu
Einzelheiten s. „Konfigurationsdatei qonline.cfg“).
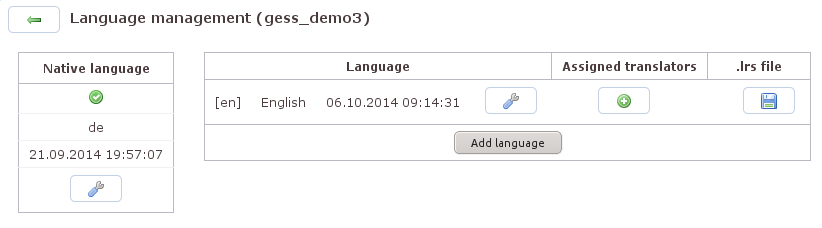
Der Kasten »Native language« erscheint im Screenshot (Abbildung 25.10, „Sprachmanagement“) ausgefüllt, weil eine Übersetzung bereits angelegt wurde. Wenn keine Übersetzung existiert, enthält der Kasten nur ein warnendes Dreieck und den Schraubenschlüssel. Mit einem Klick auf den Schraubenschlüssel erhalten wir die Möglichkeit, eine Übersetzungstabelle anzulegen. Mit dem Klick auf [Rebuild & Save] erscheint eine Auswahl, mit der die im Skript verwendete Ausgangssprache festgelegt werden kann. Wenn die Auswahl getroffen ist, generiert Q. eine zweispaltige Übersicht: links die Feldnamen, rechts die Feldinhalte. Über den Download-Knopf kann die Tabelle heruntergeladen werden. Zurück in der Übersicht zum Sprachmanagement weist der Kasten »Native language« jetzt die Ausgangssprache aus und zeigt das Datum, an dem die Ausgangstabelle angelegt wurde.
Im Kasten daneben können wir über den Knopf [Add
language] Tabellen für die Übersetzung hinzufügen.
Der Klick öffnet erneut die Sprachauswahl, mit der
wir das Kürzel für die Zielsprache dieser Tabelle
festlegen können. Anschließend weist die Übersicht
die Sprachkennung und die Sprache aus sowie das
Datum, an dem die Tabelle zuletzt verändert wurde.
Über den Schraubenschlüssel öffnet sich die Tabelle
für die Übersetzung (s.u.). Über das Pfeilsymbol
unter »Import« können vorhandene Übersetzungsdateien
(.lrs) beim Anlegen einer neuen
Übersetzung als Grundstock in die Datenbank
importiert werden. Auf diese Weise lassen sich
Sprachvarianten handhaben, wenn etwa eine vorhandene
deutsche Übersetzung für die österreichische
Variante importiert werden kann, bei der dann nur
die Abweichungen korrigiert werden müssen.
Der Klick auf das Plus-Zeichen unter »Assigned Translators« erlaubt es, jeder Sprachtabelle einen oder mehrere Übersetzer zuzuordnen. Der Klick auf das Plus-Zeichen öffnet die Auswahl für die Übersetzer und weist die Nutzernamen aus, die mit der Rolle »Translator« in der User-Tabelle (s. „Users - Benutzerverwaltung“) eingetragen und über [User Assignment] (s. „User assignment - Nutzerkonten“) der Studie zugeordnet sind. Mit einem Klick in das weiße Feld öffnet sich die Liste der Übersetzer. Ein Klick auf den Namen ordnet die Auswahl als Übersetzer zu. Aus der Liste lassen sich die einzelnen Einträge über das »x« wieder entfernen,
Nach einem Klick
auf das Diskettensymbol bietet Q. an, die
Übersetzungstabelle mit dem Dateinamen
[Sprachkennung].lrs (für Französisch z.B, »fr.lrs«)
zu speichern. Das System hinterlegt die Tabelle im
Skript-Verzeichnis, und dann kann sie im Skript über
die Anweisung readTextRessource
(s. „Actionbefehle“)
eingelesen werden.
Bei einer Änderung der Übersetzung muss nur die
Sprachtabelle erneut als als
lrs-Datei erneut abgespeichert
werden, damit sie beim nächsten Start eines
Interviews eingelesen werden kann. Wenn dagegen der
Fragebogen verändert wird, indem Fragen hinzukommen
oder Fragenamen verändert werden, müssen wir die
grundlegende Datenbanktabelle über den
Schraubenschlüssel unter »Native language« durch
einen Klick auf »Rebuild & Save« neu aufbauen.
Ein Rebuild der Skriptsprache kann jederzeit
vorgenommen werden. Neue Texte werden automatisch
ergänzt, nicht mehr vorhandene entfernt (aber nicht
aus der Datenbank gelöscht) und veränderte Texte
werden orange gekennzeichnet. Ändert man also eine
Frage von Single zu SingleGrid, dann bleiben
Fragetext/-titel, Intervieweranweisungen etc
erhalten solange der Fragename identisch bleibt.
Ändert man auch den Namen der Frage, muss man sie
komplett neu übersetzen. Ändert man im Skript alles
zum Ursprung zurück, tauchen auch die alten
Übersetzungsinformationen wieder auf (orange).
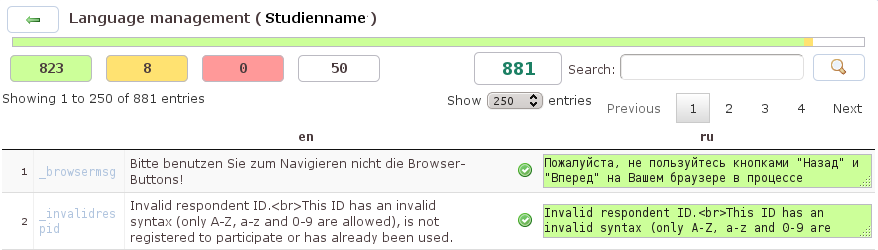
Die Abbildung 25.11, „Die Übersetzungstabelle“ zeigt eine Tabelle mit Englisch als Ausgangssprache im Skript (en) und der Übersetzung ins Russische (ru). Sortiert ist die Tabelle nach den Feldnamen; dadurch listet zeigt die Tabelle die Felder einer Frage in unmittelbarer Nachbarschaft. Q. hat in dem gezeigten Ausschnitt insgesamt 881 Felder identifiziert, die zu übersetzen sind. An 823 existierenden Übersetzungen hat das System nichts auszusetzen (links grün unterlegt). Bei acht Übersetzungen warnt Q. (gelb unterlegt), dass nach der Übersetzung der Quelltext noch einmal verändert wurde. Um die Warnung zu entfernen, muss die Übersetzung korrigiert oder bestätigt werden. Rot unterlegt das System die Anzahl der Übersetzungen, die einen möglichen Fehler enthalten, weil Elemente aus dem Quelltext (HTML-Formatierungen, Q.-Anweisungen) nicht oder fehlerhaft in die Übersetzung übernommen wurden. 50 Felder (weiß unterlegt) sind nicht übersetzt. Die Knöpfe mit der Anzahl der Felder funktionieren auch als Filter: ein Klick auf die gelb unterlegte acht zeigt in der Tabelle nur die acht noch zu überprüfenden Übersetzungen an. Ein Klick auf die 881 hebt die Einschränkung wieder auf und zeigt die erste Seite mit 250 Einträgen an.
Texte, die keinen zu übersetzenden Inhalt haben
und nur aus Schlüsselwörtern wie
@insert() oder HTML-Inhalten
bestehen, werden automatisch gefiltert.
Mit einem Eintrag im Suchfeld und dem Klick auf
die Lupe wird die Anzeige auf die Einträge
eingeschränkt, die den Suchbegriff enthalten. Das
gilt auch für die Feldnamen, so dass etwa die
Suche nach »f1_« alle Felder ausweist, die diese
Zeichenkette enthalten. Auch hier arbeiten die
Knöpfe als Filter, und wir können die Anzeige mit
einem Klick auf den gelben Knopf auf die Felder
einschränken, deren Übersetzung sich noch geändert
hat. Um die durch die Suche eingeschränkte Anzeige
aufzuheben, muss das Suchfeld geleert werden.
Der Suchbegriff QSYNTAX liefert
alle Texte mit syntaktischen Besonderheiten (z.B. HTML, Q. Befehle) zurück.
Für die eigentliche Übersetzung müssen nur die leeren Felder in der rechten Spalte ausgefüllt werden. Dabei zeigen sich einige Besonderheiten: Wenn der Cursor im nächsten Feld platziert wird, überprüft das System die Eingabe. Handelt es sich um einen häufiger auftretenden Text bietet es an, wie Abbildung 25.12, „Nachfrage: Alle Vorkommnisse übersetzen?“ zeigt, alle Vorkommnisse des Textes mit der gewählten Übersetzung zu versehen.
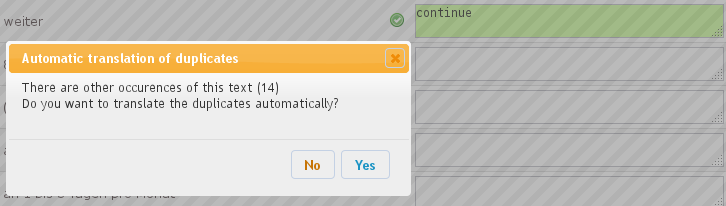
Zwischen dem Skript-Text und der Übersetzung bringt Q. mit kleinen Markierungen noch zusätzliche Informationen unter:
Ein grün unterlegter Haken bedeutet ok.
Ein rot unterlegtes Ausrufezeichen zeigt ein Problem mit der Übersetzung an und erläutert es, wenn der Mauszeiger darüber liegt.
Das grau umrandete Uhrensymbol zeigt an, dass die Übersetzung geändert wurde. Ein Klick auf das Symbol zeigt die bisherigen Versionen der Übersetzung an.
Um Studien in
mehreren Sprachen durchzuführen, müssen die Texte,
die einen Fragebogen ausmachen, übersetzt werden.
Über den Knopf [Language resource] kann eine Datei
für die Übersetzung heruntergeladen werden
(Voreingesteller Dateiname:
def_lang.lrs). Die Datei
besteht aus zwei Spalten: Die erste Spalte (bis zum
ersten Leerzeichen) enthält die innerhalb des
Fragebogens eindeutigen Bezeichner für den
jeweiligen Text, der in der zweiten Spalte (nach dem
ersten Leerzeichen) folgt.
Eine Übersetzung ordnet in einer separaten Datei den Bezeichnern (in der ersten Spalte) die übersetzten Texte in der zweiten Spalte zu - getrennt durch ein Leerzeichen. Eine solche Sprachdatei kann zu Beginn eines Interviews von Q. eingelesen werden, um den Fragebogen in der gewünschten Sprache auszugeben.
In der Regel spielt hier csv als
Austauschformat eine Rolle, weil die
Übersetzungstabelle gerne mit
Tabellenkalkulationsprogrammen wie Excel bearbeitet
wird.
Für die Fehlersuche kann es sinnvoll sein, sich das
vollständige Skript anzusehen, so wie es Q.
abarbeitet. Das bedeutet, alle Trennungen in
verschiedene Dateien, die über
include-Anweisungen
zusammengeführt werden, alle Leerzeilen, die zur
übersichtlichen Strukturierung im Skript eingefügt
wurden, hebt Q. auf und zudem werden alle Makros
expandiert. Das komplette Skript bietet Q. dann
unter dem Namen
skript_expanded.q zum Download
an.
Um einen Fragebogen vom Entwicklungssystem in die Testumgebung. auf den Produktionsserver oder auf ein Android-Gerät zu kopieren, eignet sich der Menü-Punkt [Upload].
Der Server für den Upload muss aus der ausklappbaren
Liste gewählt werden. Den Inhalt der Liste bestimmt
die Datei server.lst im
config-Verzeichnis (s. „server.lst“).
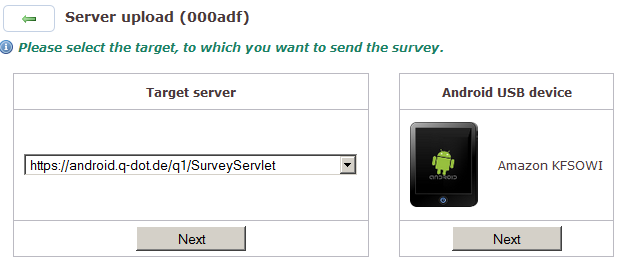
Auf dem Zielsystem muss der Nutzer unter dem gleichen Login ebenfalls ein Konto haben, das dort mindestens über die Zugriffsrechte »reduced« verfügt. Falls die Studie bereits vorhanden ist, sie womöglich nur aktualisiert werden soll, muss sie vor dem Upload auf dem Zielserver deaktiviert werden.
Beim Upload auf den Server können einzelne Bestandteile der Studie ausgewählt bzw. ausgelassen werden:
GTC folder
Das Verzeichnis
gtcmit den Anweisungen für das automatisierte Erstellen von Tabellen mittels GESStabs.Text folder
Das Skript-Verzeichnis selbst, in dem die Datei
skript.qliegen muss.Media folder
Das Medienverzeichnis der Studie mit den grafischen Elementen.
Quota
Die Dateien
quotavars.lstund, falls Beschreibungen für Quoten vorhanden sind,qdesc.lstIDs
Kopiert den lokalen Stand der ID-Listen in den Dateien
respo.lstundrespm.lst.Datasets
Kopiert die Interviews.
Config files
Kopiert die Konfigurationsdateien access.lst (s. „Nutzerkonten und Zugriffsrechte: users.lst“), active.cfg, idproperties.cfg und title.txt auf den Server. Einzelheiten zu den letzten drei Dateien finden sich in der Übersicht Konfigurationsdateien im Fragebogenverzeichnis.
Wenn Q. ein Android-Gerät am USB-Anschluss bemerkt, bietet es automatisch die Möglichkeit, die Studie auf das Gerät zu kopieren. Im Gegensatz zu den verschiedenen Server-Optionen kann die Studie nur vollständig auf Android kopiert werden. Als Option bietet das Programm nur an, das Medienverzeichnis beim Kopieren auszulassen.
Ist der zu kopierende Fragebogen auf dem Gerät bereits vorhanden, wird er durch den Upload nur aktualisiert, ansonsten wird die Studie neu angelegt. Der Unterschied macht sich auf Tablets vor allem bei den Fallnummern bemerkbar: Die Aktualisierung belässt es bei der fortlaufenden Zählung, bei neu angelegten Fragebögen beginnt die Zählung dagegen von vorn.
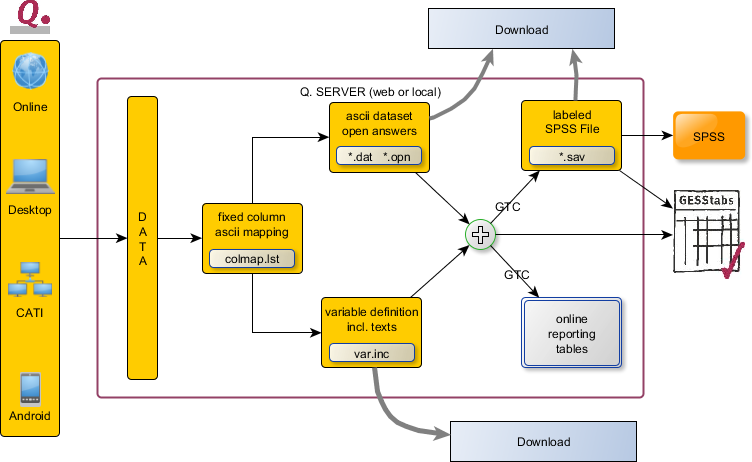
Bevor wir zum Thema Datenexport kommen, einige Informationen zu den Ausgangsdaten, den sogenannten Rohdaten.
Jedes Interview wird in einem eigenen Datensatz gespeichert. Zusätzlich zu den eigentlichen Nutzdaten, enthält der Datensatz weitere Informationen, wie z.B. Datumsangaben, Uhrzeiten, Angaben zur Dauer, bei Bedarf auch Angaben zur Dauer pro Frage.
Die Rohdaten werden unter den zur Zeit der Erhebung vergebenen Variablennamen gespeichert. Das hat den enormen Vorteil, dass man sich im Vorfeld noch keine Gedanken über eine Datensatzstruktur oder eine eventuelle Bespaltung machen muss. Selbst wenn sich nach der Hälfte der Feldzeit herausstellen sollte, dass der Kunde gerne noch eine Labelliste verlängern möchte, zwischen Frage 2 und Frage 3 gerne noch die Fragen 2a und 2b gestellt haben möchte, die Multiq anstelle von 15 Ausprägungen nun 20 haben soll, Frage 5 nun nachträglich doch gefiltert werden soll – alles kein Problem. Mit Q. gehören Spaltenverschiebungen und Spaltenpläne der Vergangenheit an.
Sehen wir uns nun einmal die Oberfläche für den Daten-Export an:
-

Zurück zum vorherigen Screen
-

Aktuellen Screen neuladen
-

Schaubild für den Datenexport aufrufen
-
Zeigt die aktuelle Anzahl an Datensätzen an. Über den Schraubenschlüssel kommen wir zum Menü
Daten editieren
-
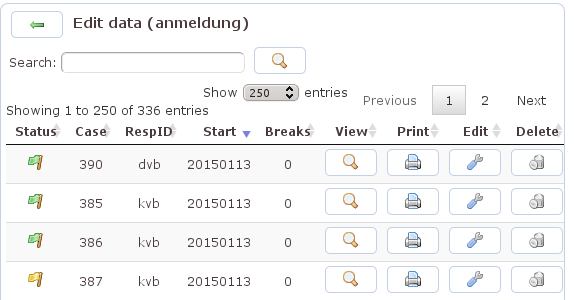
Die Seite gibt Aufschluss über die bis zum Zeitpunkt des Seitenaufrufs vorliegenden Datensätze. Die Tabelle weist mit der Flagge den Status aus (grün: beendet, gelb: nicht beendet), zeigt die vom System vergebene Fallnummer, die respondent ID, das Datum, an dem das Interview begonnen wurde, und die Anzahl der Unterbrechungen. Über einen Klick auf den Spaltenkopf kann die Übersicht nach der jeweiligen Spalte sortiert werden.
Die Icons am Ende der Zeile erlauben es, auf unterschiedliche Weise auf den jeweiligen Datensatz zuzugreifen: ansehen (Lupe), drucken (Drucker), bearbeiten (Schraubenschlüssel), löschen (Papierkorb). Mit dem Zugriff über die Lupe wird nicht einfach der Datensatz angezeigt, sondern Q. geht die einzelnen Screens durch, so wie die Befragte sie ausgefüllt hat. Da hierfür das Interview mit negativer Fallnummer noch einmal gestartet wird, kann die Interview-Ansicht parallel dazu nicht noch einmal gestartet werden. Ein erneuter Aufruf funktioniert erst, wenn das System den »künstlichen« Datensatz wieder entfernt hat.
Über den Drucker bietet das System ein Zip-Archiv von Screenshots der einzelnen ausgefüllten Screens an. Q. verwendet hier den gleichen Mechanismus wie beim integrierten Robot für Screenshots: das Interview wird mit negativer Fallnummer noch einmal gestartet und die Screens so ausgefüllt, wie es der Datensatz vorgibt (zu Einzelheiten s. „Robot: Automatisches Ausfüllen“).
Der Schraubenschlüssel öffnet ein weiteres Auswahlfenster, in dem alle Variablen des Datensatzes aufgelistet sind.
Der Schraubenschlüssel hinter jeder Variable eröffnet die Möglichkeit, den Wert der Variable zu ändern (beachten: Q. prüft an dieser Stelle die Eingabe nicht, eine SingleQ könnte auf diesem Weg also auch einen alphabetischen Wert erhalten). Über den Papierkorb kann ein Datensatz gelöscht werden. Beim Löschen werden automatisch Quoten zurückgezählt, Logeinträge entfernt und damit auch Statistiken berücksichtigt.
-
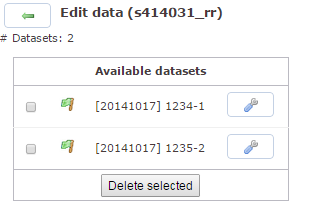
Für den ausgewählten Zeitraum haben Sie die Möglichkeit, Datensätze zu löschen. Hierfür müssen Sie das linke Kästchen anhaken und anschließend auf
Delete selecteddrücken.Bitte seien Sie vorsichtig, es gibt keine
Undo-Funktion.Ein grünes Fähnchen bedeutet es handelt sich um ein vollständiges Interview (complete). Bei einem gelben Fähnchen ist das Interview unvollständig (incomplete). Mit dem Schraubenschlüssel erreichen Sie den Datensatz und können ihn editieren.
-
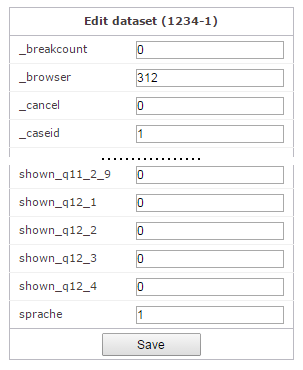
Hier befinden wir uns im Datensatz mit der Nummer 1234-1. Sie können alle Variablen für diesen Datensatz sehen und bei Bedarf Änderungen vornehmen. Haben Sie Änderungen vorgenommen, bestätigen Sie diese bitte mit
Save.Bitte seien Sie vorsichtig, es gibt keine
Undo-Funktion.Wie schon beschrieben, besteht dieser Datensatz aus den Variablennamen und den dazugehörigen Eingaben. Im nächsten Schritt werden wir aus den einzelnen Datensätzen einen Gesamtdatensatz erzeugen. Hierfür benötigen wir die sogenannte
colmap.
Am Anfang des Datenexports werden Sie folgendes sehen:

Das heißt, dem System liegen noch keine
Informationen vor, wie der Datensatz aufgebaut
werden soll. Wenn Sie den
Schraubenschlüssel drücken, liest
Q. die Datei skript.q (die
Datei, die Sie vorher einmal geskripted haben und mit
der die Daten erhoben wurden) ein und verarbeitet
sie.
Dabei erzeugt Q. eine Bespaltung und jeder Variablen
wird ein fixer Platz im Datensatz zugeordnet.
Sollten Sie einmal Ihr Skript verändern müssen, weil
Sie vielleicht die erwähnten Fragen 2a und 2b mit
aufnehmen möchten, müssen Sie anschließend auch eine
neue colmap.lst erzeugen. Dabei
zeigt sich die Stärke des individuellen Datensatzes
für jeden Befragten.
Für die bereits erhobenen Daten gab es die Fragen 2a und 2b noch nicht. Die Variablen tauchen in dem jeweiligen Rohdatensatz also nicht auf. Diese neuen Fragen bleiben für diese Befragten im Gesamtdatensatz einfach leer, da die Zuordnung innerhalb des Datensatzes über den Variablennamen und nicht über eine feste Bespaltung vorgenommen wird.
Sie sollten es allerdings vermeiden, während der Feldzeit den Variablentyp zu ändern. Dadurch kann es zu unerwünschten Seiteneffekten kommen, z.B. wenn Sie aus einer Multiq eine Numq machen. Damit würde sich auch der Variablenname von z.B. F2 zu F2.1 ändern. Aus einer Singleq eine Multiq zu machen, funktioniert dagegen gefahrlos, in die andere Richtung wird es aber ebenfalls schief gehen.
Nach Drücken des
Schraubenschlüssels erhalten wir
folgende Ansicht:
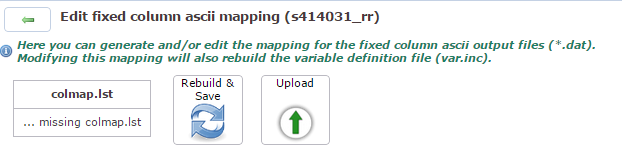
An dieser Stelle können Sie eine
colmap generieren oder auch eine
selbst erzeugte hochladen. Beschränken wir uns an
dieser Stelle einmal auf Rebuild &
Save.
Nach dem Erzeugen der
Colmap.lst sehen wir Folgendes
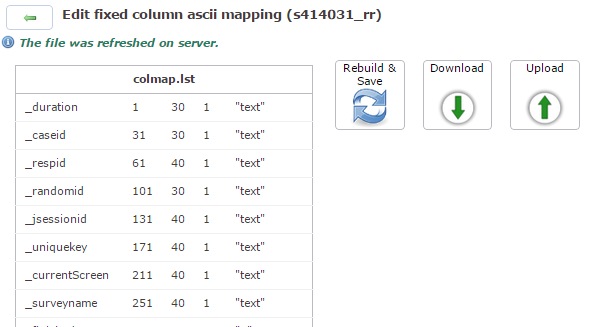
Im linken Teil sehen Sie den Inhalt der
colmap (eine Reihe der in Kapitel 9, Interne Variablen angesprochenen
internen Variablen schreibt Q. an den Anfang der
Tabelle). Die 3 Knöpfe rechts sind selbsterklärend:
Mit Rebuild & Save wird die
colmap-Datei neu erzeugt, mit
Download können Sie die
colmap herunterladen,
bearbeiten, um eventuell bestimmte Variablen nicht
mit in den Gesamtdatensatz zu übernehmen und mit
Upload können Sie diese wieder
hochladen und für den weiteren Datenexport nutzen.
Über den kleinen grünen Pfeil gelangen Sie wieder
zurück und sehen anschließend folgendes Bild:
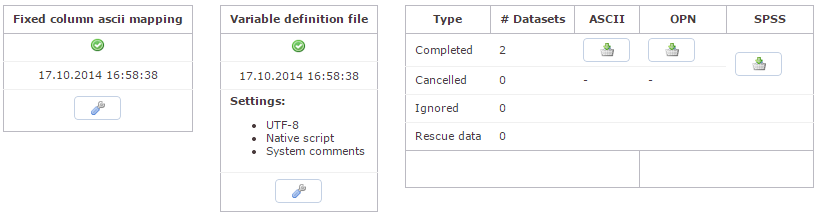
Im linken Kästchen sehen Sie, wann die
Colmap erzeugt wurde. Mit der
Colmap wird automatisch auch
ein variable definition file
erzeugt, das Sie mit GESStabs sofort weiter
verarbeiten können.
Sehen wir uns einmal den
Schraubenschlüssel im mittleren
Kästchen an. Der
Schraubenschlüssel führt uns zum
Herzstück des Datenexports, der Variablendefinition,
über die Datensätze in Kombination mit der
Colmap im Gesamtdatensatz
zusammengeführt werden.
Hier sehen Sie einen Ausschnitt aus der
var.inc (die in Kapitel 9, Interne Variablen angesprochenen
internen Variablen deklariert Q. um und setzt
sys vor den Variablennamen).
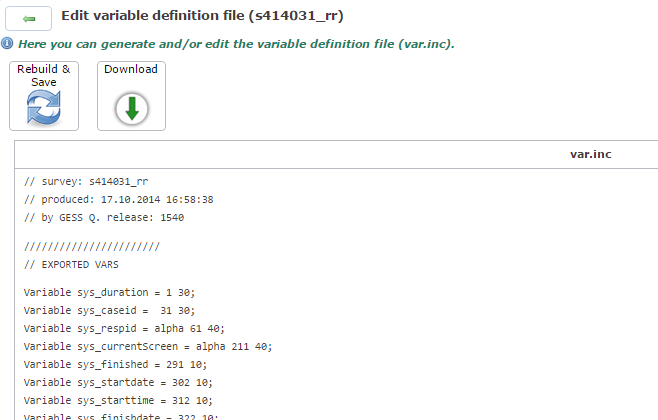
Mit Download können Sie diese
Variablendefinitionen herunterladen.
Mit Rebuild & Save können Sie
Variablendefinitionen noch an Ihre Bedürfnisse
anpassen.
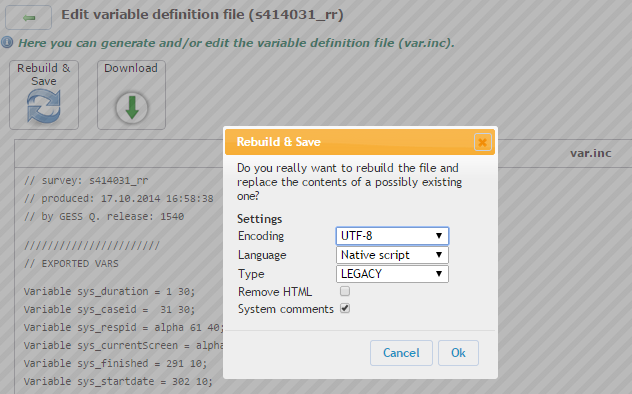
Bei Encoding können Sie die Kodierung (ANSI, UTF-8, UTF-16) einstellen, sie ist abhängig von der Plattform auf der Sie arbeiten. In der Regel müssen Sie hier nichts vorgeben.
Über den Punkt Language können
Sie die Sprache wählen, in der die
Variablendefinition ausgegeben werden soll. Haben
Sie z.B. eine Internationale Studie in mehreren
Sprachen, können Sie an dieser Stelle angeben, ob Ihr
SPSS-Datensatz in der Native-Language, also der
Sprache in der geskriptet wurde, ausgegeben wird oder
in einer anderen Sprache, die in dieser Studie
genutzt wurde.
Bei dieser Studie können Sie beispielsweise einen deutschen oder einen englisch belabelten SPSS-Datensatz erzeugen oder einen ASCII-Datensatz mit einer deutschen oder englischen Datenbeschreibung.
Mit der Einstellung legacy bei
Type entfernt Q. die Filter aus
der für die Weiterverarbeitung zentralen Datei
var.inc. Mit dieser Einstellung
sollte der Export immer funktionieren. Mit der Wahl
von normal versieht Q. die
var.inc-Datei mit mehr
Informationen und übernimmt z.B. die Filter aus dem
Fragebogen. Die können allerdings auch Hürden für
die weiter verarbeitenden Programme darstellen.
Da in Q. die Formatierungen der Befragungsscreens über HTML-Tags vorgenommen werden, diese aber nicht von jeder Software für die Weiterverarbeitung genutzt werden können, haben Sie hier die Möglichkeit, die HTML-Tags vorher zu entfernen. Das Gleiche gilt für Systemkommentare.
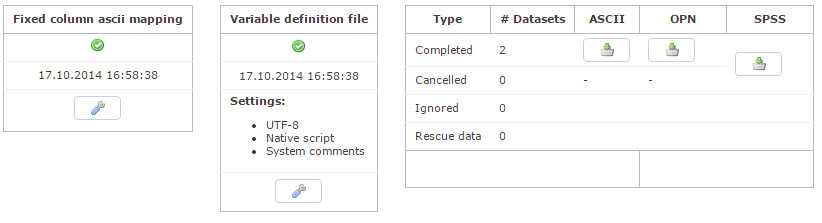
Bleibt nun noch das rechte Kästchen, hier können Sie wählen ob Sie einen ASCII-Datensatz oder einen SPSS-Datensatz erzeugen möchten – an dieser Stelle empfehlen wir Ihnen unser Basic-Tutorial für die Tabellierung, das Sie ebenfalls auf unserer Homepage finden. Darin wird anschaulich der Unterschied zwischen ASCII- und SPSS-Datensatz erläutert (http://gessgroup.de/de/content/software/gess-tabs-dokumentation).
Interessant ist der Button OPN.
Q. unterstützt neben den klassischen
Variablentypen (singleq,
numq und
multiq) auch noch andere
Variablentypen, unter anderem den Variablentyp
openq.
Dieser Variablentyp kann für offene Fragen genutzt werden, aber auch um z.B. Bilder, Tonaufnahmen oder Videos aufzunehmen. Voraussetzung dafür ist allerdings das Betriebssystem Android, das auf vielen Tablets oder Smartphones zu finden ist.
Nach Drücken des OPN-Buttons
sehen wir folgendes:
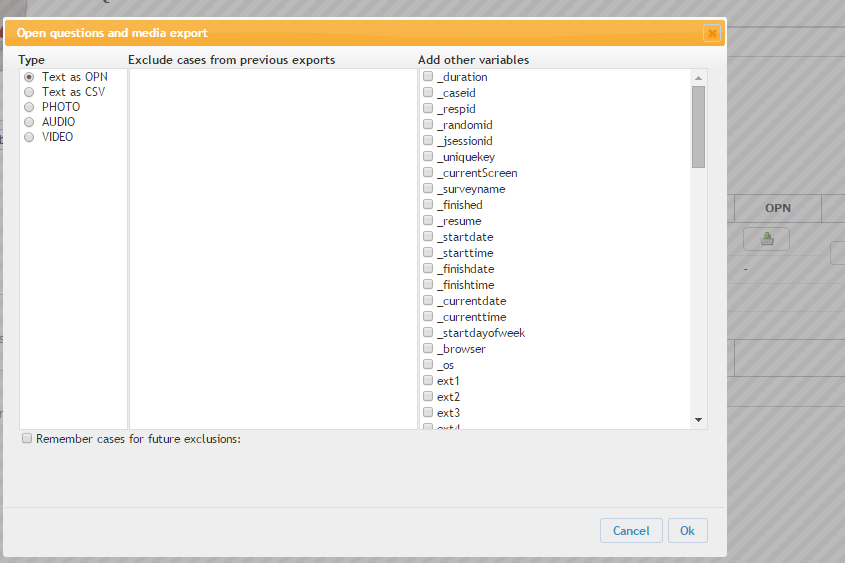
Hier können Sie die wörtlichen Nennungen entweder
als opn-Datei abspeichern, die
von GESStabs direkt weiter verwendet werden kann
oder als CSV um sie z.B. mit Excel weiter zu
verarbeiten. Zusätzlich haben Sie die Möglichkeit,
diese Dateien um weitere Variable zu ergänzen, z.B.
bei der Nachfrage zur Präferenz können Sie den
Codern noch die Variable mitgeben, in der das
präferierte Produkt abgelegt ist.
Sollte es für eine Studie Photo-, Audio- oder Videodateien geben, werden diese übersichtlich für jeden Befragten als Links in einer Excel-Datei verwaltet, aus der diese Dateien direkt aufgerufen werden können. Q. sieht in dieser Excel-Datei neben den Links zu den Multimedia-Dateien auch Felder vor, in denen z.B. die Transkriptionen eingetragen werden können.
Im Bereich »Main« informiert Q. unter dem Punkt [Overview] mit Verlaufsgrafiken über laufende, beendete und abgebrochene Interviews zu jeder aktiven Studie.
Über den Menü-Punkt Android-Manager kann ein per USB angeschlossenes Android-Gerät verwaltet werden. Q. informiert über Software und Lizenz auf dem Gerät, erlaubt das Herunterladen von Interviews und bietet mit »Net-Block« und »App-Block« an, zwei sicherheitsrelevante Aspekte von Q. auf dem Gerät zu steuern.
Die Oberfläche steuert die Google-Software adb
(Android Debug Bridge), die zusammen mit Q.
installiert wurde. Unter Windows wird das Programm
adb.exe direkt aufgerufen. Unter
Linux kann das Programm adb.exe im
Verzeichnis config/adb/ durch
einen Link auf das in der Regel systemweit
installierte Programm
/usr/bin/adb ersetzt werden:
cd config/adb
ln -sf /usr/bin/adb adb.exe
Damit Android von Q. über USB angesprochen werden kann, muss auf dem Gerät in den [Entwickleroptionen] der Punkt [USB Debugging] aktiviert sein. Die Entwickleroptionen sind normalerweise nicht sichtbar. Man kann sie einblenden indem man unter ->Einstellungen ->Über das <Gerät> sieben Mal hinter einander auf das Feld [Build Nummer] tippt.
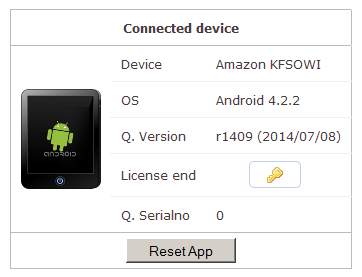
Unter »Connected Device« informiert Q. über das Gerät, die Software-Versionen und ermöglicht es, über das Schlüssel-Symbol das Gerät mit einer Lizenznummer zu lizenzieren. Der [Reset]-Knopf setzt das Gerät zurück auf Werkseinstellungen. Damit gehen auch die Lizenzierungsinformationen verloren.
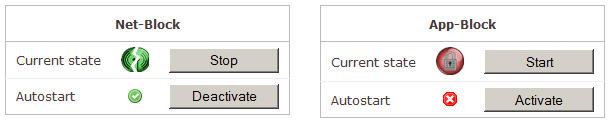
»Net-Block« blockiert Wlan, Bluetooth und Infrarot, unterbindet also jede Netzwerkverbindung. »App-Block« beschränkt den Betrieb auf dem Gerät auf Q. Android, andere Apps (etwa die Kamera) können nicht gestartet werden. Grüne Icons melden, dass die jeweilige Blockade aktiv ist bzw. die Dienste automatisch gestartet werden. Sowohl »Net-Block« als auch »App-Block« bleiben aktiv, auch wenn das Gerät neu gestartet wird. Die beiden Dienste signalisieren den Betrieb auch auf dem Eingangsschirm von Q. Android auf dem Gerät durch grüne (eingeschaltet) oder rote Icons (aus).

In der Fragebogenübersicht gibt das Programm Auskunft, welche Fragebögen auf dem Gerät vorhanden sind. Jeder Fragebogen wird mit Name und Titel und der access.lst (wer hat Zugriff auf die Studie) ausgewiesen. Unter »Completed« und »Cancelled« wird die Anzahl der vollständigen und abgebrochenen Interviews angezeigt. Sollten Mediendateien beim Interview entstehen, etwa durch Audio-Aufnahmen, erscheint hier eine dritte Spalte, in der die Anzahl der Mediendateien angegeben ist. Wenn Interviews oder Mediendateien vorliegen, erscheint neben der Zahl ein anklickbarer Pfeil, über den sich die Dateien auf den Rechner kopieren lassen. Über das Icon am Ende der Zeile kann der Fragebogen vom Gerät gelöscht werden. Bitte beachten: Interviews auf den Geräten erhalten fortlaufende Fallnummern (Geräte-Id + Fallnummer). Wird ein Fragebogen gelöscht und erneut aufgespielt, beginnt die Zählung der Fallnummern von vorn. Beim Aktualisieren des Fragebogens über [Upload] bleibt die Zählung erhalten und wird weiter geführt (s. „Android upload“).
Über die lokale Web-Oberfläche lassen sich auch neue Studien anlegen. Im Abschnitt »Main« kann über den Menü-Punkt [Survey Manager] unter dem Reiter [New] eine neue Studie mit Namen (dem Verzeichnisnamen) und einem Titel versehen werden. Der Name darf dabei, wie alle Variablennamen in Q., nur aus den Buchstaben a bis z, A bis Z, Zahlen und dem Unterstrich bestehen. Wenn vorhanden, kann der Studie über das Ausklappmenü [Use model] zusätzlich eine Vorlage für die Gestaltung des Fragebogens mitgegeben werden. (Der Menü-Eintrag »Survey Manager« steht auf Server-Installationen nicht zur Verfügung, da lokal erstellte Studien per Upload auf den Server kopiert werden können, s. „Server upload“)
Mit dem Klick auf [Create] legt Q. ein Verzeichnis mit dem gewünschten Namen unterhalb des »surveyPath« an und eines unterhalb von »mediaRoot« (die beiden Variablen enthalten die bei der Installation eingestellten Pfade, s. „Konfigurationsdatei qonline.cfg“). Ins Media-Verzeichnis kopiert Q. die grafischen Bestandteile der ausgewählten Vorlage, ins Fragebogenverzeichnis eine ganze Reihe von Dateien, deren Funktion erläutert werden soll.
Bei der Auswahl der Vorlage greift Q. auf Vorlagen zurück,
die es in CONFIG/models findet
und illustriert sie mit Vorschaubildern aus
SERVER-ROOT/model_previews. Die
Auswahl der Vorlagen lässt sich natürlich auch
erweitern.
Unter dem Reiter [Import] bietet Q. die Möglichkeit, eine Q.-Projektdatei zu importieren, so wie sie unter [Configure] über den Button [Export] exportiert wurde. Aus Sicherheitsgründen schlägt der Import fehl, wenn im Studien- oder im Archiv-Ordner ein Verzeichnis mit dem Namen der Studie bereits existiert.
Konfigurationsdateien im Fragebogenverzeichnis
- access.lst
Die Datei enthält die IDs der Nutzer, die auf die Studie zugreifen können sollen. Die Datei ist Teil der gewählten Vorlage.
- active.cfg
In der Datei selbst steht schlicht »dummy«, da sie nur als Schalter dient, der dem Server anzeigt, ob die Studie aktiv ist oder nicht. Wenn die Datei nicht vorhanden ist, beantwortet der Server den Aufruf des Fragebogens mit der Meldung »The survey is currently inactive«, ansonsten erscheint der Fragebogen. Die Datei kann im Abschnitt »Surveys« unter dem Menü-Eintrag [Configure] mittels der Veränderung des Status angelegt ([Activate]) oder gelöscht werden ([Deactivate]).
- idproperties.cfg
Die Datei legt anhand von Schlüsselworten fest, ob Teilnehmer eine ID benötigen, und wie der Variablenname für eine ID lautet:
acceptUnknown=[yes|no] Sollen Teilnehmer mit unbekannter ID auf den Fragebogen zugreifen dürfen? Voreinstellung: yes.
testMode=[yes|no] Soll der Fragebogen auch im Testmodus erreichbar sein? Voreinstellung: yes.
urlName=[zeichenkette] In der URL, mit der Teilnehmer auf den Fragebogen zugreifen, erhält ihre ID einen Variablennamen (z.B. respid=12345). Panels etwa haben höchst unterschiedliche Vorstellungen wie die Variable heißen sollte. Voreinstellung: respid (für respondent id).
- title.txt
Die Datei enthält den Titel der Studie, wie er beim Anlegen des Fragebogens über den [Survey Manager] im Feld »Title« eingetragen wurde.
Dateivorlagen im Fragebogenverzeichnis unter
text
- skript.q
Für Q. bildet die Datei
skript.qim Textverzeichnis eines Fragebogens immer den Ausgangspunkt. Über die gewählte Vorlage wird ein Beispiel, das als Ausgangspunkt dienen kann, in das Text-Verzeichnis kopiert.- formats.q
formats.qwird über den include-Mechanismus in der Dateiskript.qin das Skript eingebunden.
Im Bereich »Main« erhalten wir über den Link [Users]
eine Übersicht aller Nutzer. Die Übersicht ist
unsortiert (sie bildet den Inhalt der Datei
users.lst ab) und weist jeden
Benutzer mit fünf Feldern aus:
company
Die Firma, der ein Nutzer angehört.
name
Der Login-Name für den Nutzer.
password
Der Server legt die Passwörter in dieser Datei als einen Hash, einen Fingerabdruck des eigentlichen Passworts ab. Bei jeder Anmeldung wird dann der Hash des eingegebenen Passworts ermittelt und mit dem hinterlegten Fingerabdruck verglichen.
id
id beinhaltet die eindeutige Bezeichnung eines Kontos.
access
Das Feld weist die Zugriffsrechte aus (zum Thema Zugriffsrechte s. „Nutzerkonten und Zugriffsrechte: users.lst“).
Das Ende der Tabelle bilden drei Knöpfe, mit denen die Konten auf dem System verwaltet werden können:
New user
Nach dem Klick erscheint eine Maske, die Felder für Company, Login-Name, Passwort und ID bereithält. Die Einträge dürfen nur aus alphanumerischen Zeichen bestehen: a-z A-Z 0-9. Company, Name und Passwort müssen vorgegeben werden, wie das Sternchen es andeutet, die ID wird gegebenfalls aus den Feldern Company und Name zusammengesetzt. Die ID des Kontos muss eindeutig sein.
Remove user
Das über den Radio-Button am Anfang der Zeile markierte Konto wird mit dem Klick auf den Knopf entfernt.
Edit user
Das über den Radio-Button am Anfang der Zeile markierte Konto kann mit dem Klick auf den Knopf geändert werden.
Die Web-Oberfläche von Q. wird in jedem Fall nicht das
Passwort selbst sondern nur den SHA1-Fingerabdruck
hinterlegen. Wenn ein Passwort im Klartext hinterlegt
werden soll, muss die Datei
users.lst im
config-Verzeichnis editiert
werden.
Unter dem Punkt [Help] finden sich Links zu den kontinuierlich fortgeschriebenen Hinweisen zu neuen Entwicklungen im Readme und zur Präsenz von GESS GmbH und Q. bei Youtube, Facebook und Google+.
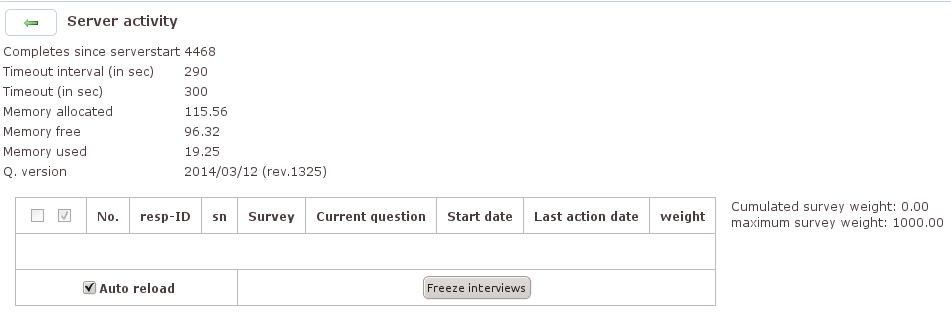
Unter [Server status] gibt Q. Auskunft über die Speicherauslastung und die Softwareversion. Über das Lupen-Symbol hinter dem Feld »Q. Version« lässt sich prüfen, ob eine neuere Version der Software vorliegt.
Außerdem verrät das Programm, welche Fragebögen aktuell ausgefüllt werden, wieviele Interviews gerade stattfinden und welche Frage die Interviewten gerade beantworten. Ein Haken bei »Auto reload« sorgt dafür, dass die Daten kontinuierlich aktuell gehalten werden. Über den Knopf [Freeze interviews] können laufende Interviews, die in der Liste markiert wurden, angehalten bzw. in den Abbruchzustand versetzt werden. »Auto reload« sollte für die Auswahl der anzuhaltenden Interviews abgeschaltet werden.
Dieses Kapitel erklärt die Integration von GESStabs zu Zwecken des Onlinereportings als flexible Kundenschnittstelle. Folgende Arbeitsschritte sind nötig, um GESStabs studienbegleitend zur Tabellierung des Ist Datenbestands einer Studie einzusetzen:
Einrichtung von GESStabs auf dem Befragungsserver (einmalig)
Definition der Tabellen
Kundenspezifische Tabellierjobs
Ausgehend von einer vorhandenen GESStabs Installation (für
Informationen hierzu sei auf die GESStabs Dokumentation
verwiesen) sind im Q.
Konfigurationsfile zwei Angaben zu
machen: Der Pfad zum Studienverzeichnis
gtcSurveyDir
, der Pfad zur ausführbaren
GESStabs Applikation
gtcApp
. Das Beispiel
zeigt eine denkbare Konfiguration:
gtcSurveyDir=/home/gessuser/surveys
gtcApp=/home/gessuser/gtc/gtc
Jede Tabellierung in GESStabs startet mit der
Ausführung eines .tab-Files, das sich im
Studienordner neben text im
Ordner gtc befinden muss.
Erfolgt keine explizit andere Zuweisung (s. „Kundenspezifische Tabellen“) heißt das
.tab-File per Default a.tab. Q.
stellt für jede Tabellieranfrage Kopien der
automatisch gepflegten ASCII und OPN Datensätze
bereit, siehe „Daten und Export“.
Zusammen mit einer Kopie der dort ebenfalls zu
findenden Variablendefinition
(var.inc) stellen diese Dateien
die Datenbasis für GESStabs dar:
cmpl_tabs.dat- Completes im ASCII Formatcmpl_tabs.opn- Offene Nennungen der Completes im OPN Formatbrk_tabs.dat- Cancelled im ASCII Formatbrk_tabs.opn- Offene Nennungen der Cancelled im OPN Formatvar_tabs.inc- Variablendefinition
Die a.tab-Datei mit den
Tabellieranweisungen kann hiermit nun frei
definiert werden. Wenn sie nicht vorhanden sein
sollte, hilft sich Q. indem es eine
Standardvorlage
dera.tab-Datei
aus /CONFIG/gtc/ an seine
Stelle kopiert und verwendet. Üblicherweise druckt
dieser Standardfall eine einfache Auszählung über
alle enthaltenen Variablen der Completes (s.u.).
Wie der Standard aussehen soll, lässt sich
wiederum frei definieren.
encoding = latin1;
splitchar = ~;
stylefile = style.css;
trimstrings = yes;
citefirstvar = TOPTEXT yvalid;
datafile = cmpl_tabs.dat;
casenumber = 31 30;
openqfile = cmpl_tabs.opn;
include = var_tabs.inc;
html = htmltabs;
codebook;
end;
Für verschiedene Kunden bzw. deren Logins können
spezifische Tabellen hinterlegt werden. Dies lässt
sich mit mehreren Tabellierdateien realisieren,
die sich den Login
IDs zuordnen lassen. Logins ohne
explizite Zuordnung bekommen per Default das
a.tab . Die Zuordnung ist
optional und kann über die Benutzeroberfläche in
der Studienkonfiguration vorgenommen werden.